Date: Thursday, May 23, 2024
Work Undertaken Summary
Risks
Time Spent
2.5hr dev container. 1hr reading 3.25hr initial AI with llama3 and phi3 1hr tweaking storytransformer output to use different tags (for easier processing of start and end of sections) and for filtering for only lead stories 4hr Storyweaver:
- Started with phi3 and it got stuck in output loops
- Tweaked temperature and beam count with limited success
- Good results but only for first 2k ish characters
- Switch to llama3, good results to 3k characters
- refine the prompt until it starts outputting more what is wanted at about 8k characters
Questions for Tutor
Next work planned
Read the prompting guide from meta: Prompting | How-to guides (meta.com)
Change examples to use the actual story format Maybe change the delimiters to be more generic like start-story and end-story. Double check if mistral-instruct-0.3 is trash Change storytransformer to search for and care about lead stories
Raw Notes
pytorch/.devcontainer/README.md at main · pytorch/pytorch (github.com)
pytorch/.devcontainer/Dockerfile at main · pytorch/pytorch (github.com)
pytorch/.devcontainer/cuda/environment.yml at main · pytorch/pytorch (github.com)
Had to mount using a volume as else it complained. think it might have actually just been complaining about mouting anything at /
Reading
New models added to the Phi-3 family, available on Microsoft Azure | Microsoft Azure Blog Tiny but mighty: The Phi-3 small language models with big potential - Source (microsoft.com)
[2404.14219] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (arxiv.org)
They say that phi3 punches above its weight with language understanding but due to its size doesn’t store much “inbuilt” knowledge. But given that we are providing the information that doesn’t seem like a detractor for our use case. Also only understands english, which is fine.
RULER
hsiehjackson/RULER: This repo contains the source code for RULER: What’s the Real Context Size of Your Long-Context Language Models? (github.com) Shows that llama3 doesn’t really degrade between 0-32k tokens. phi3 mini degrades to worse than llama2 but still pretty respectable and is the smallest model. Give them 2 weeks then if they haven’t updated the benchmark consider running it ourselves with llama3 7B and phi 7b and 14B.
Running the model
Had to provide an example to get it to just return the expected result rather than a “Here is the description you asked for”.
Turned down the temperature to make it less creative, then changed do_sample to false to force to not be creative.
<?xml version="1.0" encoding="utf-8"?>
<root>
<system_prompt>You are a helpful assistant tasked with creating a description of a vertical slice of a software system.
You never hallucinate information, if you are unsure you omit the information.
The user will descibe what the area of the system relates to, the current description of the area and a list of stories that have been completed.
You will then provide a new description of the area that includes only the relevant information from the stories.
The user will provide the current version of the between [existing documentation] and [first story]
Stories are delimited by the [next story] token.
You will output ONLY the complete new description of the area.
</system_prompt>
<example>
<prompt>Describe Applications</prompt>
<batch>Applicants can create a user to complete the application</batch>
<batch>Existing applicants can see a list of applications and can create or edit their applications</batch>
<batch>Internal users can see a list of applications, edit or approve.</batch>
<input>Applications is a form which propspective users fill out to request services.</input>
<output>Applications is a form which propspective users fill out to request services.
From the applications list applicants and internal users can:
- Create
- Edit
Internal users can:
- Approve
</output>
</example>
<test>
<prompt>Describe the Leads functional area.</prompt>
<batch>Internal users can email a lead to the supplier for quoting</batch>
<batch>A lead can be edited by a customer service admin</batch>
<batch>A lead can be deleted</batch>
<batch>A lead contains:
- Name
- Reference
- Created Date
- Status
- New
- In Progress
- Complete
- Completed Date</batch>
<batch>Add a new lead status quoted, which is set when the supplier replies to the quote</batch>
<batch>Internal users can complete a lead, which sets the completed date</batch>
<input>Internal users can create a lead (permission required)</input>
</test>
<testoutput>
Leads is a functional area where internal users can create, manage, and track leads. Internal users can:
- Create a lead
- Email a lead to the supplier for quoting
- Edit a lead (customer service admin permission required)
- Delete a lead
- Complete a lead, which sets the completed date
A lead contains the following information:
- Name
- Reference
- Created Date
- Status (New, In Progress, Complete, Quoted)
</testoutput>
</root>Llama3 8B - 8bit
Leads is a functional area where internal users can create, manage, and track leads. Internal users can:
- Create a lead
- Email a lead to the supplier for quoting
- Edit a lead (customer service admin permission required)
- Delete a lead
- Complete a lead, which sets the completed date A lead contains the following information:
- Name
- Reference
- Created Date
- Status (New, In Progress, Complete, Quoted)
phi3 small (7B) - 8bit
The Leads functional area allows internal users with the appropriate permissions to:
- Create a lead, which includes fields for Name, Reference, Created Date, Status (New, In Progress, Complete, Quoted), and Completed Date.
- Email a lead to the supplier for quoting.
- Edit a lead.
- Delete a lead.
- Complete a lead, which sets the Completed Date.
Additionally, a new “Quoted” status is available for leads, which is set when the supplier replies to the quote.
phi3 medium (14B) - 4bit
Leads is a functional area where internal users can create, edit, and delete leads. It requires permission to create a lead. A lead contains the following information:
- Name
- Reference
- Created Date
- Status (New, In Progress, Complete)
- Completed Date
A lead can be emailed to the supplier for quoting. Once the supplier replies, the lead status can be updated to ‘quoted’. A lead can be edited by a customer service admin. Internal users can also complete a lead, which sets the completed date.
Llama3 70B - no quant
Only used about 8% gpu. Basically no ram usage. Vram at 14GB seems to mostly be just reading from disk at 500MB/s
Traceback (most recent call last):
File "/workspaces/StoryWeaver/weaver.py", line 71, in test_prompt
response = model.test()
File "/workspaces/StoryWeaver/llm/basic_model.py", line 92, in test
result = self._run_messages(next_messages)
File "/workspaces/StoryWeaver/llm/llama3.py", line 41, in _run_messages
outputs = self.model.generate(
File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py", line 1758, in generate
result = self._sample(
File "/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py", line 2397, in _sample
outputs = self(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 166, in new_forward
output = module._old_forward(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py", line 1183, in forward
logits = self.lm_head(hidden_states)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 161, in new_forward
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py", line 328, in pre_forward
value = self.weights_map[name]
File "/usr/local/lib/python3.10/dist-packages/accelerate/utils/offload.py", line 118, in __getitem__
return self.dataset[f"{self.prefix}{key}"]
File "/usr/local/lib/python3.10/dist-packages/accelerate/utils/offload.py", line 171, in __getitem__
tensor = f.get_tensor(weight_info.get("weight_name", key))
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.96 GiB. GPU
OutOfMemoryError('CUDA out of memory. Tried to allocate 1.96 GiB. GPU ')
An error occurred, please try again
Did not finish after 3 hours.
StoryTransformer Changes
Leads was out of order because one card was made like 4 months before the others but the order wasn’t optimal. So the initial assumption about just basing off the created date wasn’t sufficient for leads.
As this was the only story I’ve decided to update the stories created date to more accurately reflect its location in the timeline.
update Tickets Set CreatedUtc='2024-06-27' where Id=131421
Tag Remover
The fuzzy text match caused results for before the major feature was developed to be surfaced. To prevent this I added a ‘tagger’ that removes any tags added for stories prior to a certain date e.g. if a story was matched that was before the initial development then it can safely be ignored.
StoryWeaver - Testing 14b phi3
Problem - It can get stuck in local minima and so repeatedly output the same text in a loop. Only discovered after
- 3e, Any Lead/Notes, Lead/Documents, Lead/Communications should be copied to any new or existing Company records
Leads & Opportunities - Documents
Leads & Opportunities - Communications
Leads & Opportunities - Actions
Leads & Opportunities - Notes/Audit
Leads Lookups
New lookups, which will be used on Leads, as follows:
- New Reasons type lookup of "Lead Cancellation" (with other Reasons lookups)
- New Reasons type lookup of "Lead Loss" (with other Reasons lookups)
- Lead Probability
Leads & Opportunities - Documents
Leads & Opportunities - Communications
Leads & Opportunities - Actions
Leads & Opportunities - Notes/Audit
Leads Lookups
New lookups, which will be used on Leads, as follows:
- New Reasons type lookup of "Lead Cancellation" (with other Reasons lookups)
- New Reasons type lookup of "Lead Loss" (with other Reasons lookups)
- Lead Probability
Leads & Opportunities - Documents
Leads & Opportunities - Communications
Leads & Opportunities - Actions
Leads & Opportunities - Notes/Audit
Leads Lookups
Started testing various temporatures to see if they are any better.
Increasing by 0.2 each time.
0.2 got stuck. 0.4 got stuck but on reports, which is fair enough as they are very complicated.
0.8 - 04 temp loop After about 1733 characters it started just spitting out the stories verbatim, maybe something to do with the 4k ish base context causing it to start dying around 1.7x2 = 3.5k words.
temp 0.8 started to hallucinate work being either completed or in progress. Interestingly it started generating in the style we use for new cards
Tried to use beams (5) but ran out of memory. Tried to use beams (3) but it never completed, assumedly got stuck in a generation loop like before.
Trying with llama3, might need to try models with specifically longer context sizes, or maybe try creating a skeleton with different headers that it can out content under, and running against each header rather than for the section overal.
llama3 completed! interestingly the final result was around 1.7k characters… Is the system pairing things down to stay within some limits or did it just get confused?
At this commit it got confused and removed some important detail. https://gitea.4man.dev/lukethoma5/story-weaver-output/commit/f27796d0b6d36284d1477a1e306aec6305b27131
Going to try re-generating with a longer allowed generation. Failing that going to add the important detail back and see if it tries to cut it again.
Increasing the limit came to the same out-come. going to try and add the detail back.
It’s definitely culling the information, trying to keep it to a certain size. will retry without telling it to be consise and see what it does.
It wasn’t being told to be consise.
I told it You will NOT remove any information from the existing documentation, unless that information has been contradicted by a later story. and the output jumped from 1600 characters to 2700 characters. With seemingly all the important information still there.
It is still removing important functionality 144415, 144416 in Leads - Leads & Opportunities - Convert, Cancel, other Status changes · 453734e017 - story-weaver-output - Gitea: Aeternus (4man.dev) but less than before.
It takes about 10 minutes to run through all the stories. now taking much much longer after making it print out more. It took about 40 minutes Could look to having it output a diff rather than the full thing to increase speed? Could look at creating the skeleton as just various headers Could look at improving the prompt to be more precise and give examples of how to interpret the various fields. Could try again with phi3 now that we know that llama3 can do it. phi3 immedaitely got stuck in a loop again after the first batch, never mind
It works surprisingly well!
It added content in the right places!
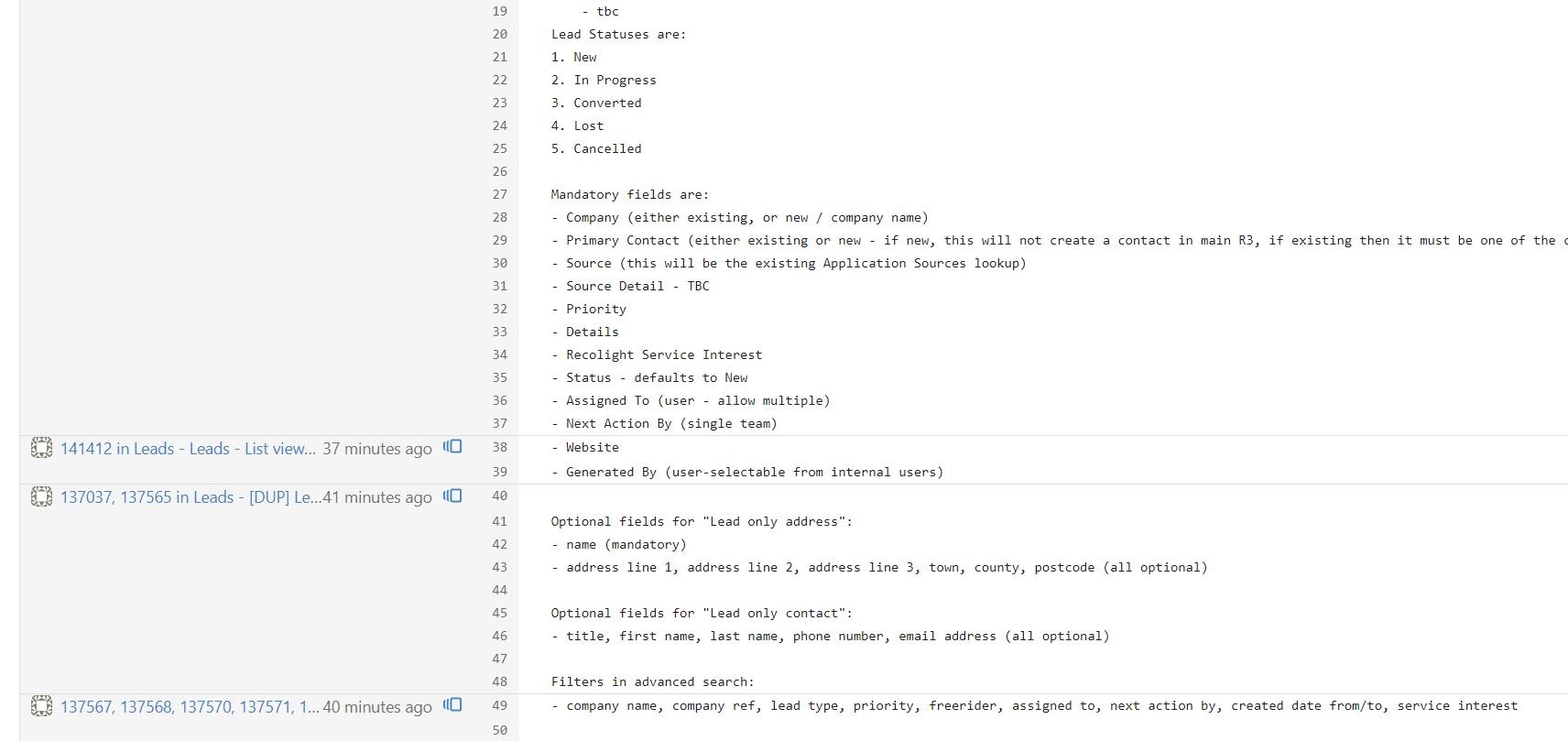
Latest version is 8k characters… yippe, worked so much better on llama than on phi3.
Trying to get it to output a diff instead only led to it outputting the whole thing as a blank document into a completely new document.