Date: Monday, March 04, 2024
Work Undertaken Summary
- Complete and Submit TMA01
- Investigate and understand:
- Tensors
- Natural Language Processing (NLP)
- Different kind of transformers / Transformer Architecture and their applications
- Encoder only
- Decoder only
- Encoder-Decoder transformers
- Transfer Learning
- Attention Layers
- Tokenisation techniques and their applications
- Word-based
- Character-based
- Subword-based
- Batching
- Long Sequences
- Normalization and pre-tokenization
- Optimisation Techniques
- Quantization - Running LLM’s with lower precision to cut memory cost
- Flash Attention - Changing memory usage scaling from quadratic to linear
- Prototype implementation of StoryTransformer
- Investigate and fail to get flashattention running on AMD hardware
- Investigate and procure Nvidia Card
Risks
Current risk: Total cost of compute, work out how much input there is going to be to know how much it would cost to load all the data.
Action to resolve: Do initial extraction of user stories to get sense of scale. Create initial version of StoryTransformer
Resolution: Total wordcount for all user stories is 440k words. So total token size is likely 880k words. Prohibitively expensive to run in the cloud + data sovereignty issues. Must look into Large Context Local LLM’s.
Risk: Flash attention really important to project viability (long context length). Is built on CUDA so might be Nvidia specific.
Action to resolve: ROCm/flash-attention: Fast and memory-efficient exact attention (github.com) suggests that flashattention CAN work on AMD cards. Timebox of 1 day to try and get flashattention running locally with huggingface.
Resolution: Despite the claims by AMD flash attention does not work, at least on their consumer hardware. Due to the requirement of a long context window I require flashattention. Have invested in a new GPU specifically for this project.
Next Action: Get Large Context Local LLM running with Nvidia GPU and preform needle in haystack test.
Time Spent
- 1.5hrs TMA01
- 1.25hr on NLP and tensors.
- 4.1 hr on hugging face course / using transformers.
- 2.5hr on llm memory implications.
- Tues - 3hr on rocm setup with flashattention
- Tues 1hr on testing model ability to combine text
- Weds 1hr on flashattention/flashattention2 papers.
- 3.25hr on Data Transformer
- 1.25hr on Nvidia Card
Questions for Tutor
Next work planned
Get Nvidia card Look into prompt engineering, really need to prevent the AI from just fabricating everything.
Continue investigating architectural innovations: Optimizing LLMs for Speed and Memory (huggingface.co)
Setup hugging face and try and enable flash attention due to large contexts to be used. GPU inference (huggingface.co)
Look into What is Text Generation? - Hugging Face
Look into [2010.11934] mT5: A massively multilingual pre-trained text-to-text transformer (arxiv.org)
Look into Text-to-Text Transfer Transformer (T5)
Look into What is Text Generation? - Hugging Face
It looks like our task matches closest with causal language modeling.
Raw Notes
NLP Course
How do Transformers work? - Hugging Face NLP Course
![]() attention is all you need focused around translation tasks [1706.03762] Attention Is All You Need (arxiv.org)
attention is all you need focused around translation tasks [1706.03762] Attention Is All You Need (arxiv.org)
The Transformer architecture was introduced in June 2017. The focus of the original research was on translation tasks. This was followed by the introduction of several influential models, including:
-
June 2018: GPT, the first pretrained Transformer model, used for fine-tuning on various NLP tasks and obtained state-of-the-art results
-
October 2018: BERT, another large pretrained model, this one designed to produce better summaries of sentences (more on this in the next chapter!)
-
February 2019: GPT-2, an improved (and bigger) version of GPT that was not immediately publicly released due to ethical concerns
-
October 2019: DistilBERT, a distilled version of BERT that is 60% faster, 40% lighter in memory, and still retains 97% of BERT’s performance
-
October 2019: BART and T5, two large pretrained models using the same architecture as the original Transformer model (the first to do so)
-
May 2020, GPT-3, an even bigger version of GPT-2 that is able to perform well on a variety of tasks without the need for fine-tuning (called zero-shot learning)
Different kind of transformers
- GPT-like (also called auto-regressive Transformer models)
- BERT-like (also called auto-encoding Transformer models)
- BART/T5-like (also called sequence-to-sequence Transformer models)
How they are trained
trained on large amounts of raw text in a self-supervised fashion. The models understand language but not tasks
The general pretrained model then goes through a process called transfer learning. During this process, the model is fine-tuned in a supervised way — that is, using human-annotated labels — on a given task.
Tasks:
- causal language modeling
- An example of a task is predicting the next word in a sentence having read the n previous words. This is called because the output depends on the past and present inputs, but not the future ones.
- masked language modeling
- in which the model predicts a masked word in the sentence.
Transfer Learning
This pretraining is usually done on very large amounts of data. Therefore, it requires a very large corpus of data, and training can take up to several weeks.
Fine-tuning, on the other hand, is the training done after a model has been pretrained. To perform fine-tuning, you first acquire a pretrained language model, then perform additional training with a dataset specific to your task
Tensors
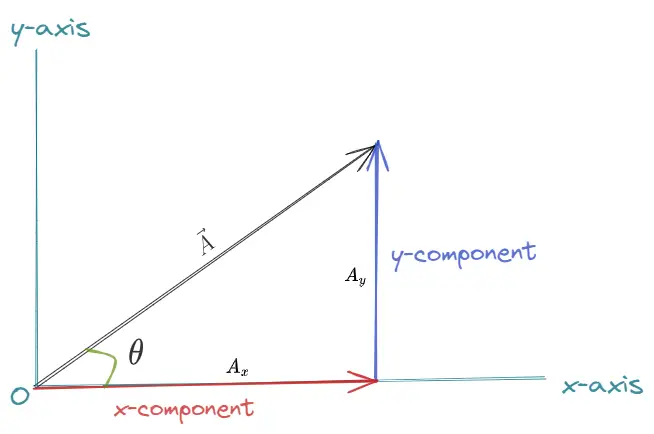
Vectors: an arrow representing a quantity with both magnitude and direction.
while a vector can be used for representing velocity. It can also be used to represent an area, the magnitude being equal to the m^2 of the area and the arrow perpendicular to the surface.

Vectors exist in a coordinate system (e.g. Cartesian. x-y-z). Coordinate basis vectors = unit vector in e.g the x or y or z axis. E.g. the direction is in 1 of the coordinate axis. e.g. x^, y^ or z^ unit vectors = vectors with a magnitude of 1
To find the x-component you project the vector onto the x axis. same for y axis.
 What’s a Tensor? - YouTube
What’s a Tensor? - YouTube

Vectors are “tensors of rank 1”. Only 1 directional indicator (basis vector) per component. 1 index/basis vector per component. Scalars are “tensors of rank 0”. 0 basis vectors per component, e.g. they don’t have any direction.
![]() A rank 2 tensor (in 3d space). Has 9 components and 9 SETS of two basis vectors.
The components now have two indicies. E.g. A(xx) A(xy)
A rank 2 tensor (in 3d space). Has 9 components and 9 SETS of two basis vectors.
The components now have two indicies. E.g. A(xx) A(xy)
![]()
E.g. A(xx) might refer to the x directed force on a surface who’s area vector is in the x direction. A(yx) might be the y directed force on a surface whos area vector is in the x direction.
Rank 3 tensor
![]() 27 components, each pertaining to one of 27 sets of 3 basis vectors. Each component has 3 indices
27 components, each pertaining to one of 27 sets of 3 basis vectors. Each component has 3 indices
Why tensors
All observers, regardless of reference frames, agree (not on the basis vectors, not on the components but on the combination of components and basis vectors).
The basis vectors transform one way between reference frames, and the components transform in such a way as to keep the combination of the two the same for all observers.
- Dan Fleisch
Transformer Architecture
![]()
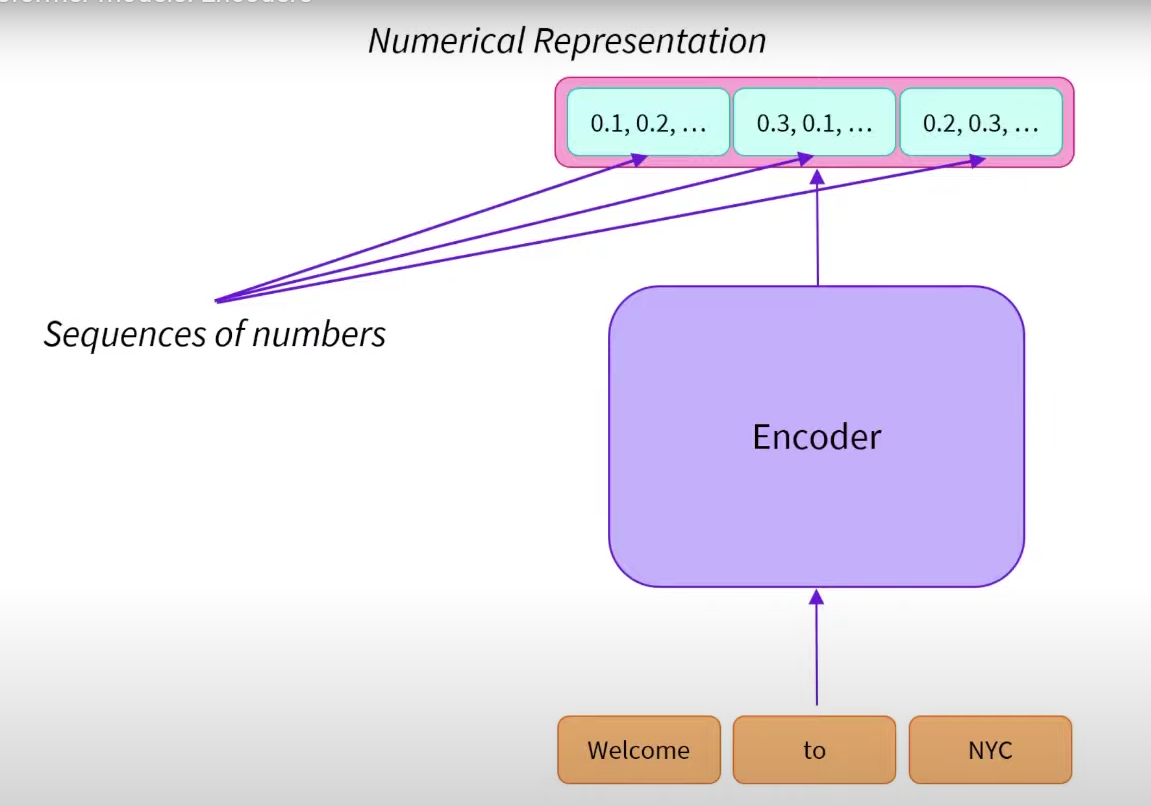
The encoder encodes text into numerical representations. Numerical representations can also be called embeddings or features.
Encoder is bi-directional. Decoder is uni-directional.
When combined they are known as an encoder-decoder / sequence-to-sequence transformer.
It’s auto-regressive as we use the previous output in the next output.
-
Encoder (left): The encoder receives an input and builds a representation of it (its features). This means that the model is optimized to acquire understanding from the input.
-
Decoder (right): The decoder uses the encoder’s representation (features) along with other inputs to generate a target sequence. This means that the model is optimized for generating outputs.
-
Encoder-only models: Good for tasks that require understanding of the input, such as sentence classification and named entity recognition.
-
Decoder-only models: Good for generative tasks such as text generation.
-
Encoder-decoder models or sequence-to-sequence models: Good for generative tasks that require an input, such as translation or summarization.
Attention layers
A key feature of Transformer models is that they are built with special layers called attention layers. In fact, the title of the paper introducing the Transformer architecture was “Attention Is All You Need”!
this layer will tell the model to pay specific attention to certain words in the sentence you passed it (and more or less ignore the others) when dealing with the representation of each word.
a word by itself has a meaning, but that meaning is deeply affected by the context, which can be any other word (or words) before or after the word being studied.
Attention is all you need
The Transformer architecture was originally designed for translation.
In the encoder, the attention layers can use all the words in a sentence.
The decoder, however, works sequentially and can only pay attention to the words in the sentence that it has already translated. the first attention layer in a decoder block pays attention to all (past) inputs to the decoder, but the second attention layer uses the output of the encoder. It can thus access the whole input sentence to best predict the current word.
The attention mask can also be used in the encoder/decoder to prevent the model from paying attention to some special words — for instance, the special padding word used to make all the inputs the same length when batching together sentences
For example, BERT is an architecture while bert-base-cased, a set of weights trained by the Google team for the first release of BERT, is a checkpoint. However, one can say “the BERT model” and “the bert-base-cased model.”
Encoder Models
The encoder outputs one sequence of numbers per input word. The numerical representation of the word can be called a feature vector or feature tensor.
The dimension of the vector is defined by the architecture of the model. For base BERT it is 768.
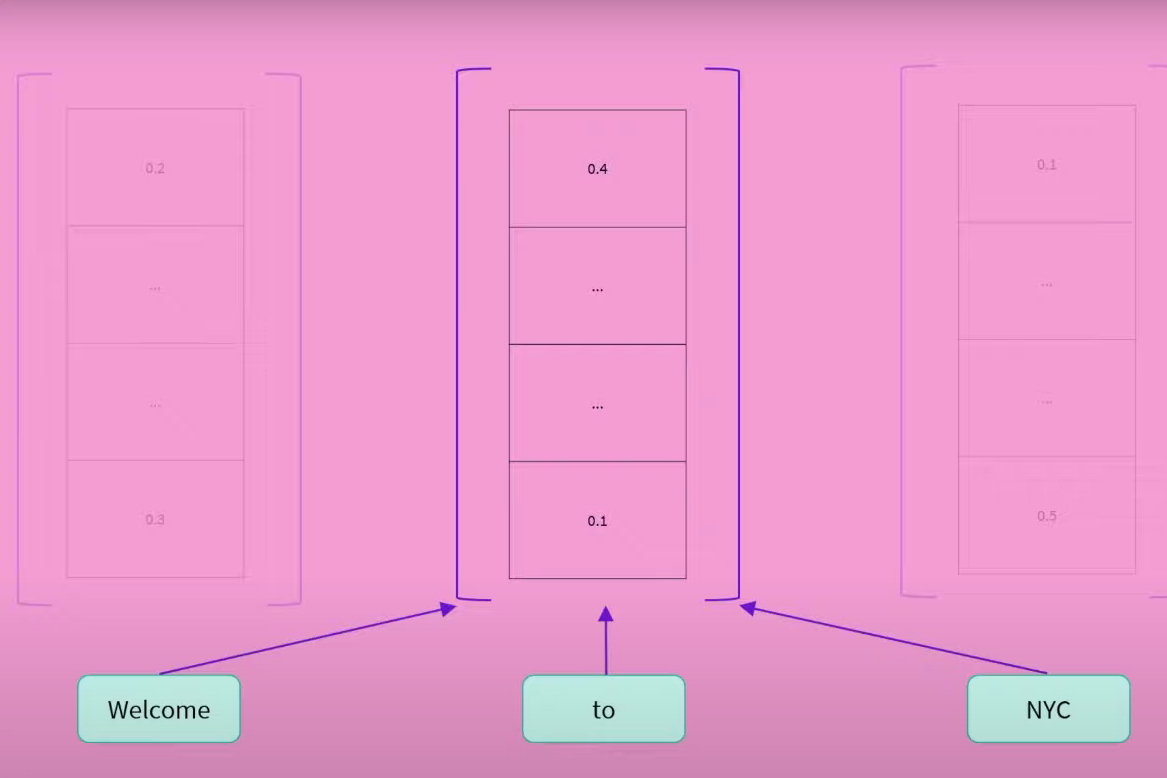
Each vector is influenced by every other words representation. e.g. context is embedded in. In this case “to” is influenced by welcome and NYC. The left context and the right context. It gives a contextualised value.
The vector of 738 values holds the meaning of the word within the text.
Uses of a standalone encoder:
- Bi-directional: context from the left and the right
- good at extracting meaningful information
- sequence classification, question answering, masked language modeling
- Natural Language Understanding
Encoder models use only the encoder of a Transformer model. At each stage, the attention layers can access all the words in the initial sentence. These models are often characterized as having “bi-directional” attention, and are often called auto-encoding models.
Research
OpenAI GPT model was proposed in Improving Language Understanding by Generative Pre-Training
OpenAI GPT-2 model was proposed in Language Models are Unsupervised Multitask Learners
Decoder Models
Decoder models use only the decoder of a Transformer model. At each stage, for a given word the attention layers can only access the words positioned before it in the sentence. These models are often called auto-regressive models.
These models are best suited for tasks involving text generation.
GPT-2 is a decoder only architecture.
Can generally use a decoder for all tasks of an encoder, but with sacrificed performance.
Decoders primarily differ in their use of masked self attention. It can only read context in one direction. E.g. the output of “To” is completely independent of the word NYC.
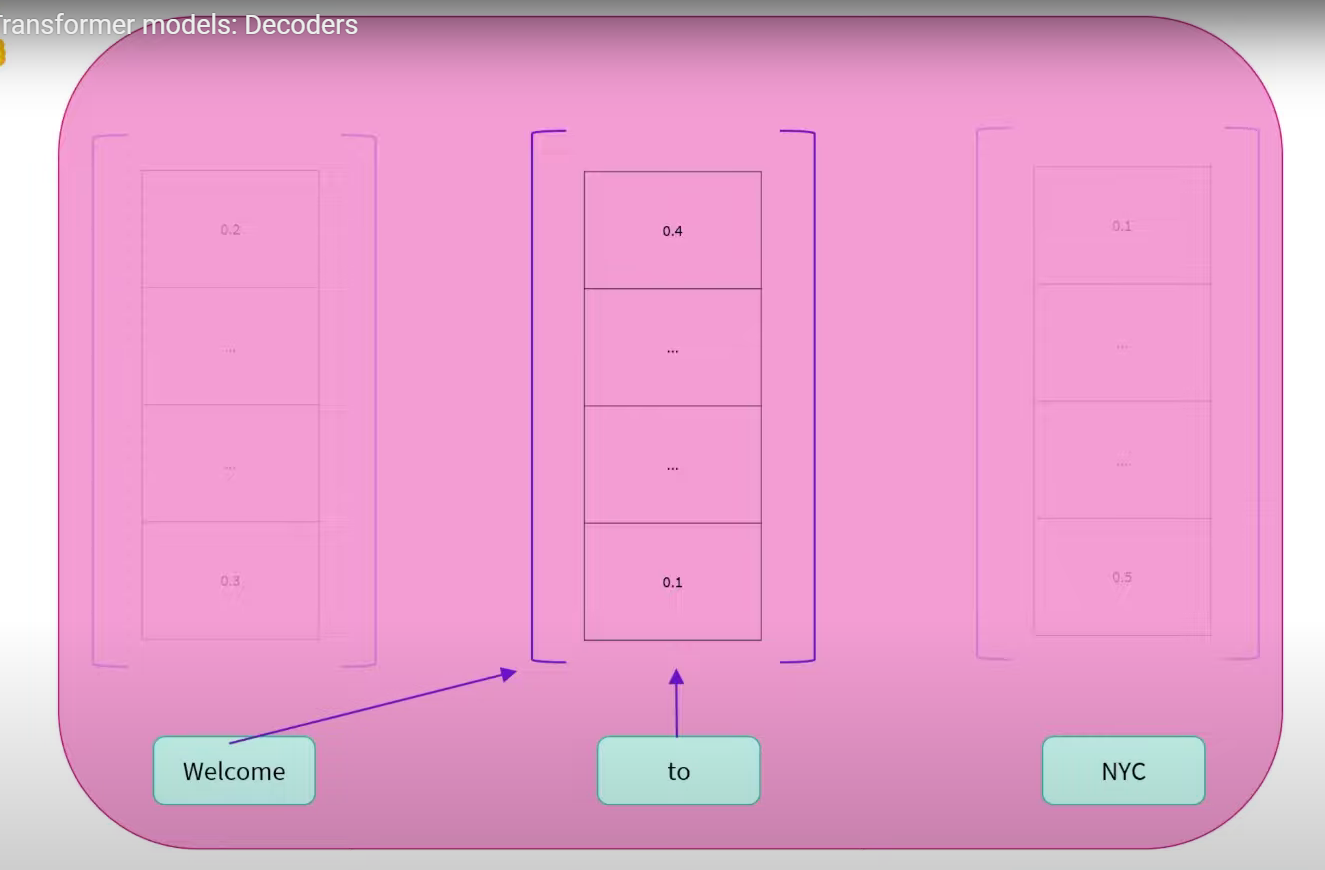
The right context is masked / unavailable.
Uses of decoder-only
- unidirectional: access to their left or right only
- natural language generation. Very good at completing a sequence of words e.g. the rest of a sentence. Also called causal language modelling.
- example gpt-2 Auto-regressive models reuse their past outputs as inputs in the following steps.
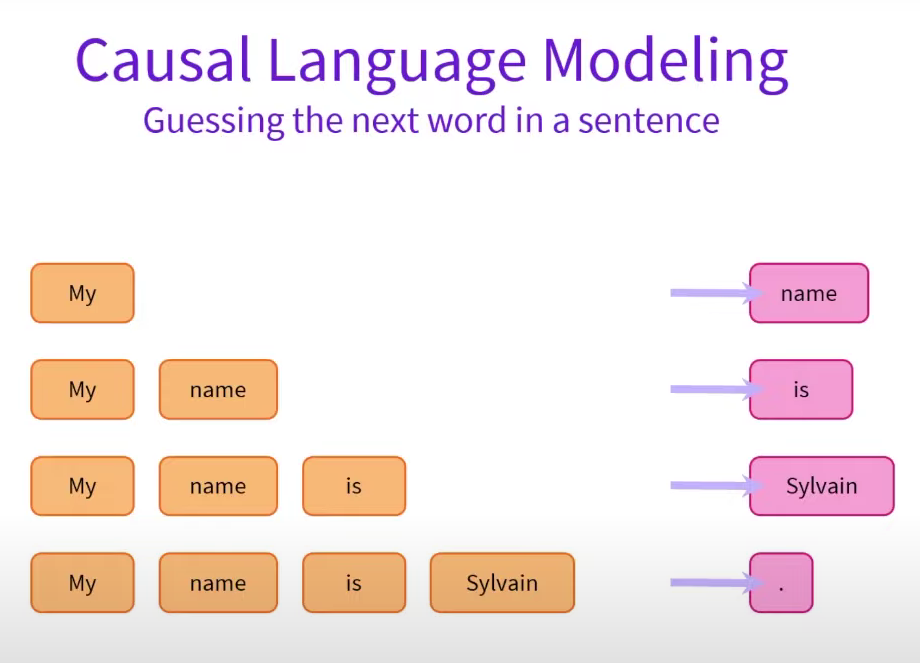
Encoder-Decoder models
Encoder-decoder models (also called sequence-to-sequence models) use both parts of the Transformer architecture.
Translation is also called transduction.
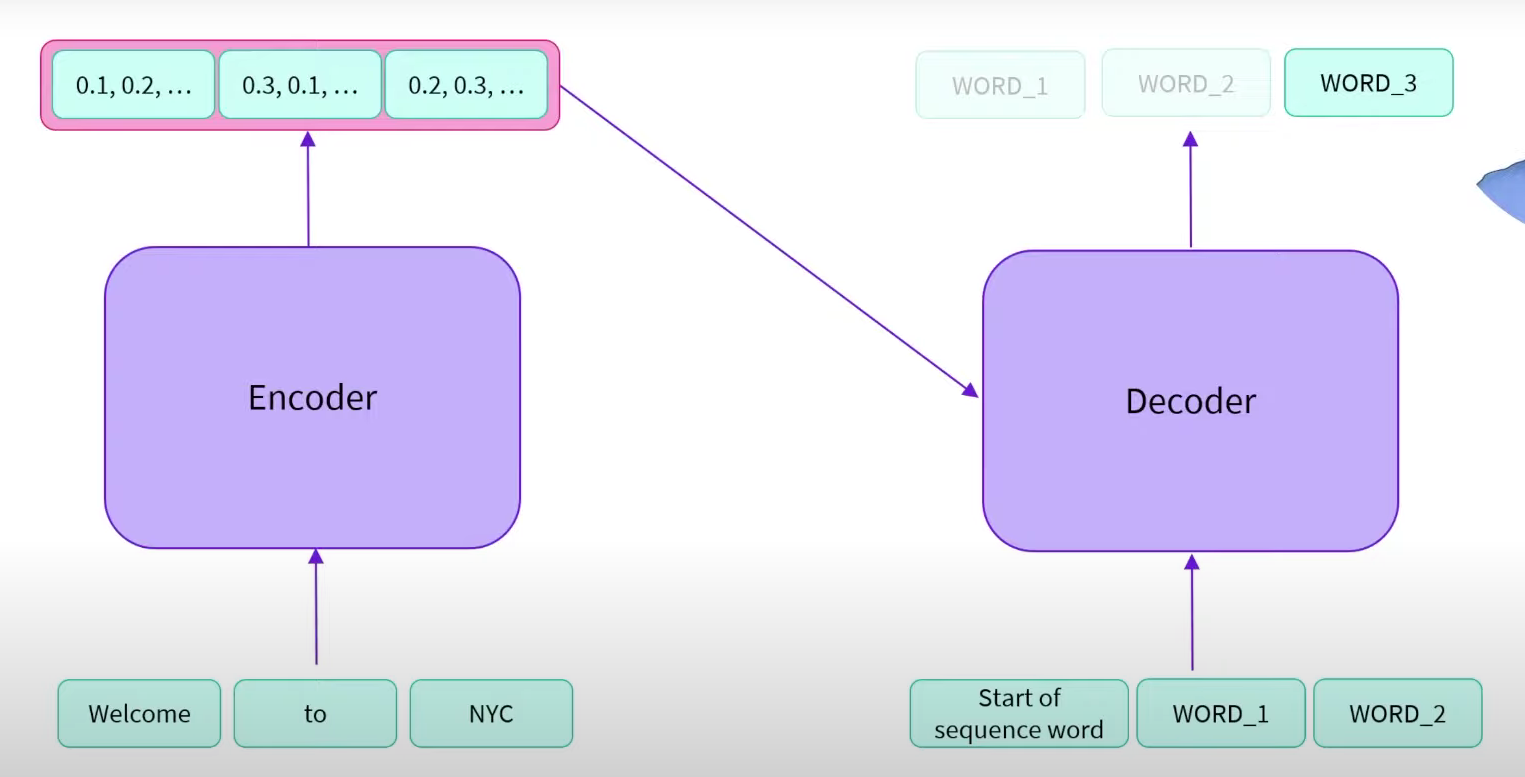
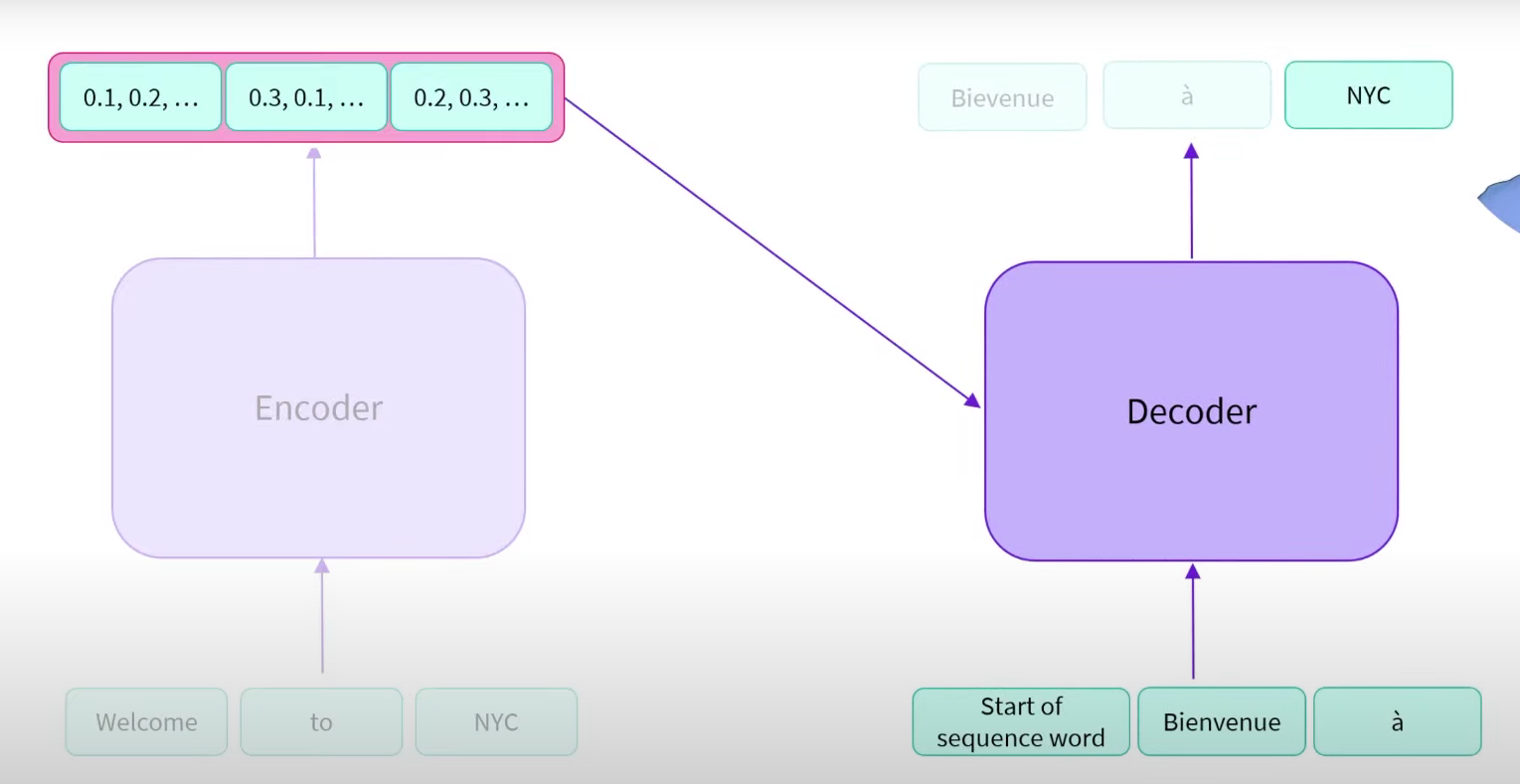
The encoder is ran once and outputs a sequence of vectors representing the whole context / sentence “Welcome to NYC”. The decoder takes the encoder output, plus all the previous text it has generated to generate the next word in the sequence.
E.g. the encoder output stores the entire English sentence that it is trying to translate. The previous text from the decoder is the partially translated sentence.
Benefits
Sequence to sequence tasks; translation, summarization
Weights are not necessarily shared across encoder and decoder. Input and output sequence can be independent of input length. They also handle variable output lengths. This can be controlled by having different context lengths for encoder and decoder.
Pipelines

Tokenisation
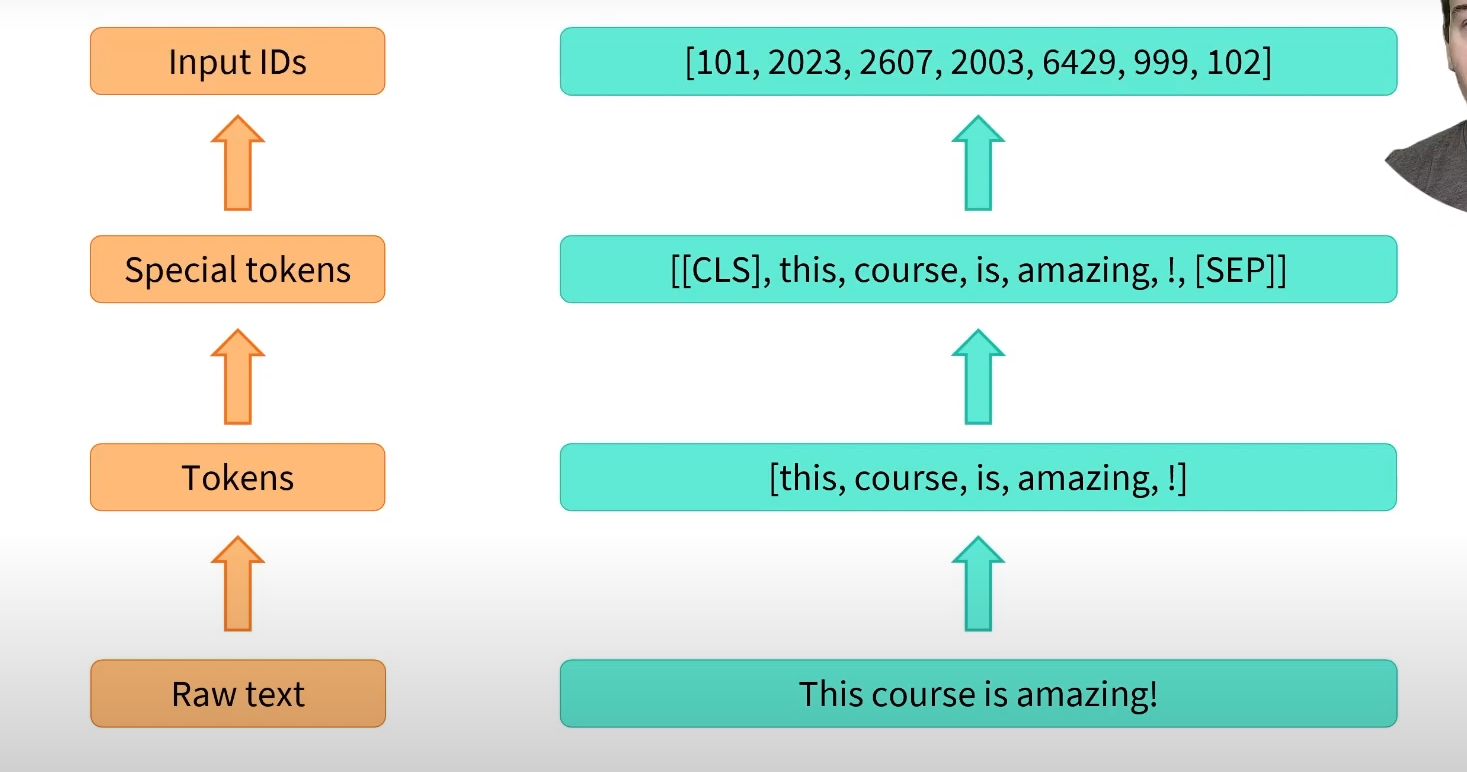
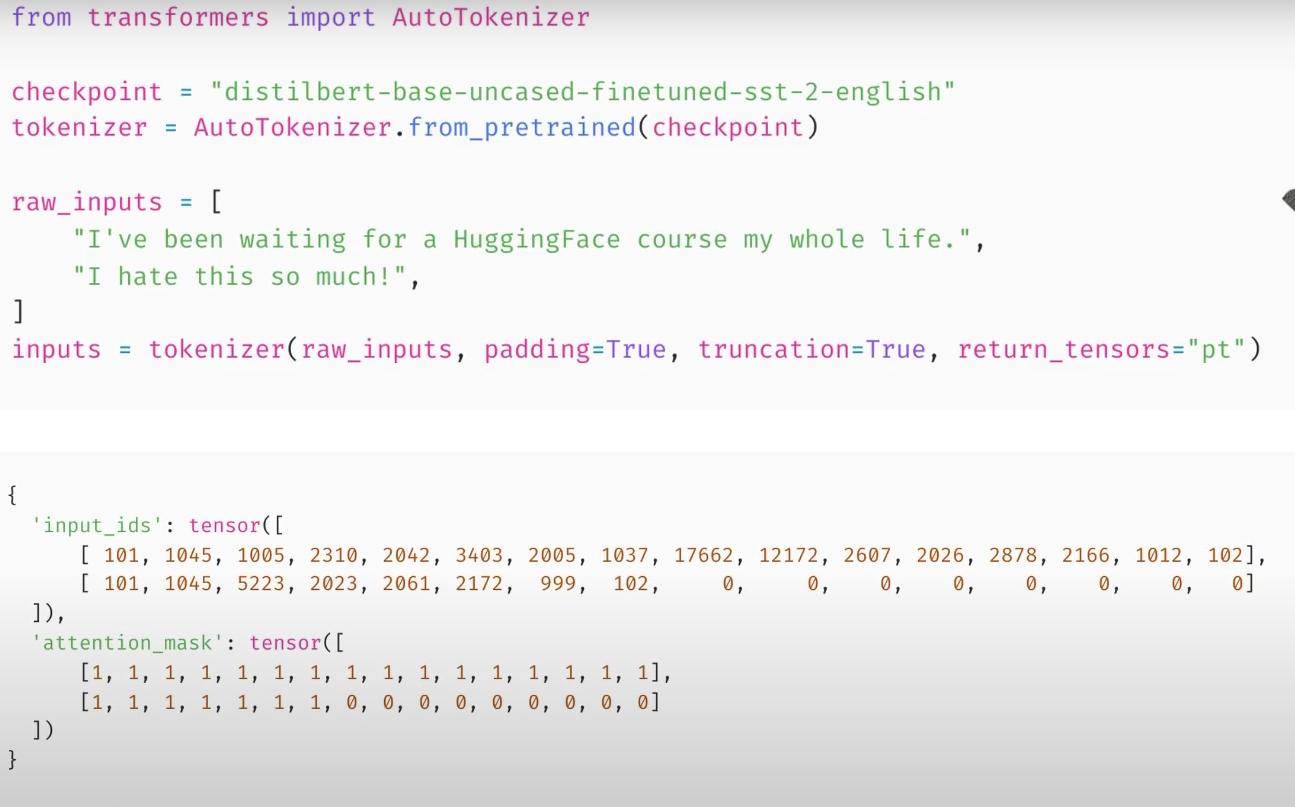
return_tensors=“pt” means pytorch tensors. The input is scaled to the same length for use in batching. The attention mask is used to make the model ignore the padding for the second sentence.
Note the presence of the special tokens. 101 indicating the start of a sentence and 102 indicating the end.
tokenizer convert the text inputs into numbers that the model can make sense of.
- Splitting the input into words, subwords, or symbols (like punctuation) that are called tokens
- Mapping each token to an integer
- Adding additional inputs that may be useful to the model
All this preprocessing needs to be done in exactly the same way as when the model was pretrained
Using the model
The vector output by the Transformer module is usually large. It generally has three dimensions:
- Batch size: The number of sequences processed at a time (2 in our example).
- Sequence length: The length of the numerical representation of the sequence (16 in our example).
- Hidden size: The vector dimension of each model input.
It is said to be “high dimensional” because of the last value. The hidden size can be very large (768 is common for smaller models, and in larger models this can reach 3072 or more).
In Chapter 1, the different tasks could have been performed with the same architecture, but each of these tasks will have a different head associated with it.
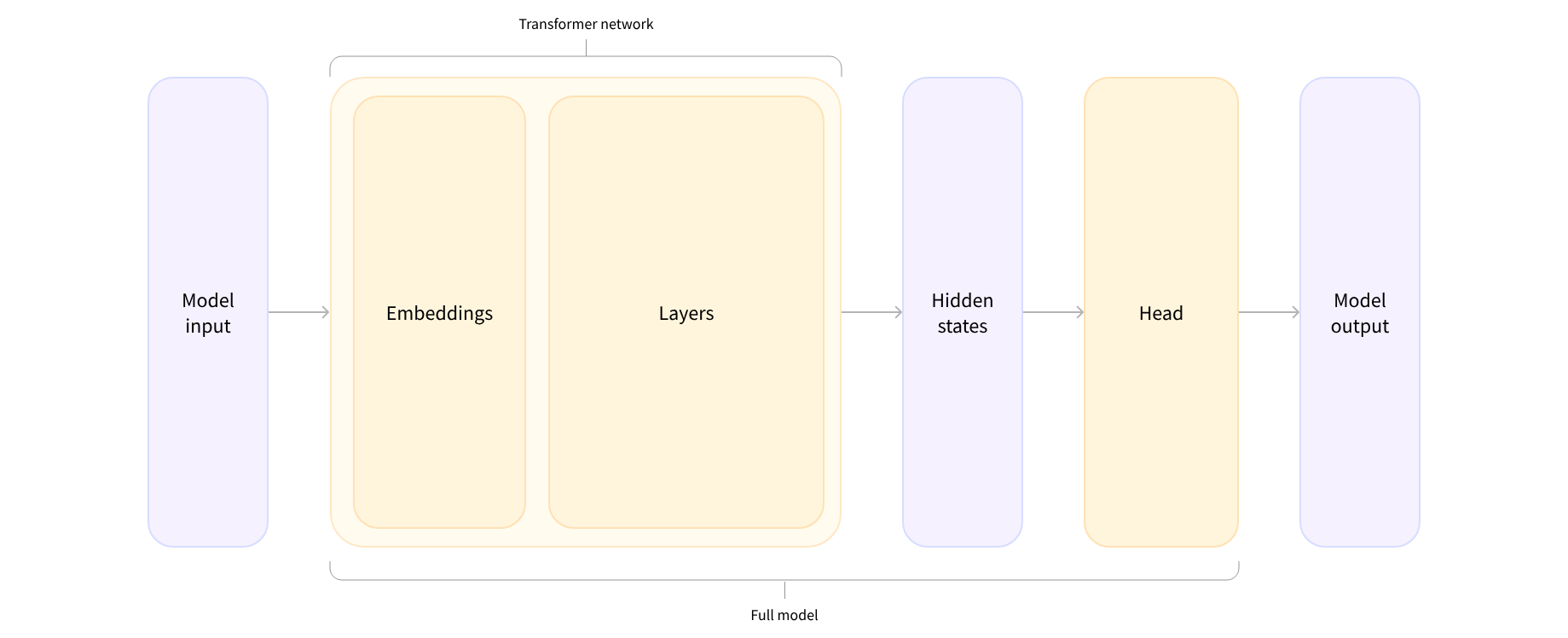
The embeddings layer converts each input ID in the tokenized input into a vector that represents the associated token. The subsequent layers manipulate those vectors using the attention mechanism to produce the final representation of the sentences.
Postprocessing
Our model predicted [-1.5607, 1.6123] for the first sentence and [ 4.1692, -3.3464] for the second one. Those are not probabilities but logits, the raw, unnormalized scores outputted by the last layer of the model. To be converted to probabilities, they need to go through a SoftMax layer (all 🤗 Transformers models output the logits, as the loss function for training will generally fuse the last activation function, such as SoftMax, with the actual loss function, such as cross entropy)
Init-ing models
The weights have been downloaded and cached (so future calls to the from_pretrained() method won’t re-download them) in the cache folder, which defaults to ~/.cache/huggingface/transformers. You can customize your cache folder by setting the HF_HOME environment variable.
Creating a random initalised model
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# Model is randomly initialized!using a pre-trained model. It uses the checkout name. e.g. the saved-state at that time. If you’ve created your own the checkout can be a path.
Note I should probably use the AutoModel rather than BertModel as BertModel is a specific model whereas automodel handles different architectures.
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")Let’s say we have a couple of sequences:
sequences = ["Hello!", "Cool.", "Nice!"]The tokenizer converts these to vocabulary indices which are typically called input IDs. Each sequence is now a list of numbers! The resulting output is:
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]import torch
model_inputs = torch.tensor(encoded_sequences)Tokenizers
Top level tokenization algorithms
- Word-based
- Character-based
- Subword-based
Word-based tokenizers
Split each word into its own token.
Each word gets assigned an ID, starting from 0 and going up to the size of the vocabulary. The model uses these IDs to identify each word.
It’s very intuitive however has downsides:
- Different forms of the same word get different ids. e.g. dog and dogs are distinct even though they are very similar concepts
- The vocabulary (total set of words) can get very very large, this can be reduced by limiting to only top X words with everything else mapped to an unknown token. Bit obviously this leads to information loss. there are over 500,000 words in the English language.
Finally, we need a custom token to represent words that are not in our vocabulary. This is known as the “unknown” token, often represented as ”[UNK]” or ”<unk>”
Character-based tokenizers
Character-based tokenizers split the text into characters, rather than words. This has two primary benefits:
- The vocabulary is much smaller.
- There are much fewer out-of-vocabulary (unknown) tokens, since every word can be built from characters. Since the representation is now based on characters rather than words, one could argue that, intuitively, it’s less meaningful: each character doesn’t mean a lot on its own, whereas that is the case with words. However, this again differs according to the language; in Chinese, for example, each character carries more information than a character in a Latin language.
Another thing to consider is that we’ll end up with a very large amount of tokens to be processed by our model: whereas a word would only be a single token with a word-based tokenizer, it can easily turn into 10 or more tokens when converted into characters.
Subword-based tokenizers
Subword tokenization algorithms include:
- WordPeice (BERT)
- Unigram (ALBERT)
- Byte-Pair Encoding (GPT-2)
subword tokenization is the “best of both worlds approach”. Common words get a single token to represent them. Rarer words can be decomposed while keeping their meaning. E.g. the meaning of “annoyingly” is kept by the composite meaning of “annoying” and “ly”.
They keep meaning between different words by keeping their root-s together.
Encoding
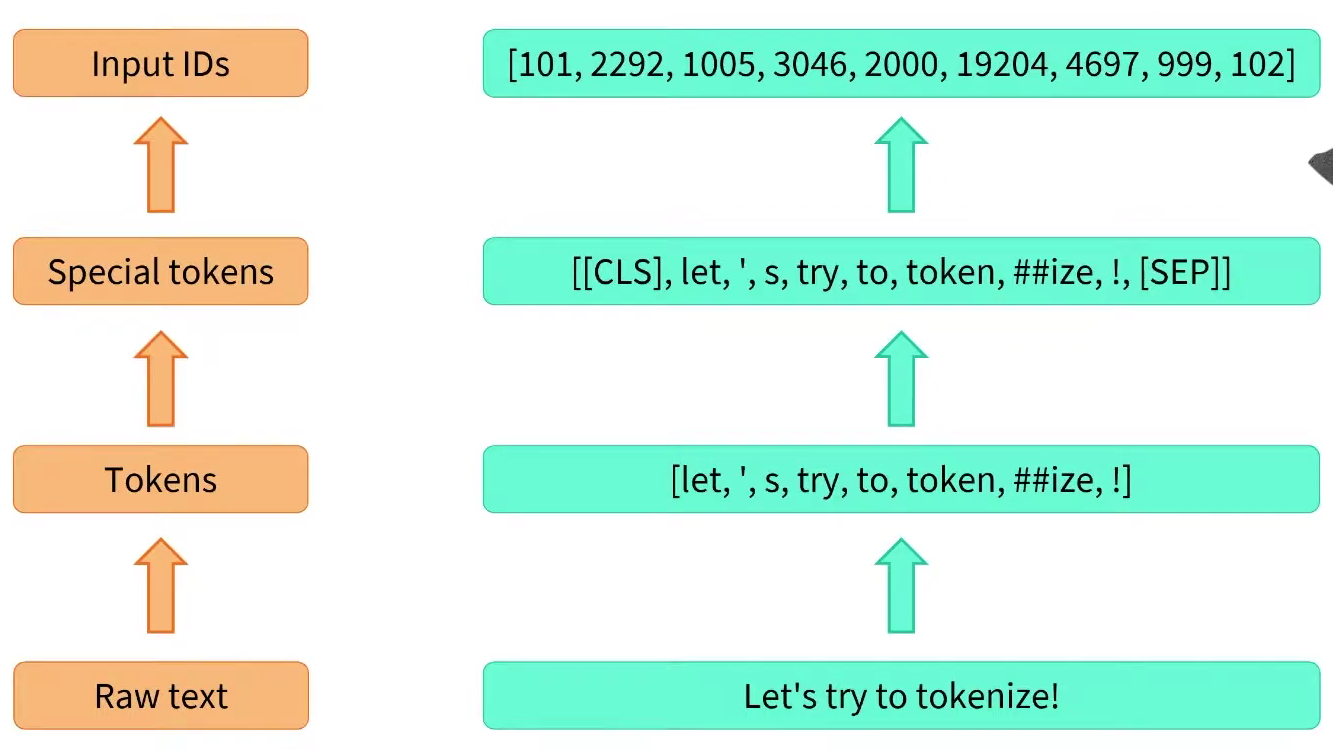
The vocabulary needs to be exactly the same as what was used when the model was trained. E.g. the algorithm (to transform text into many tokens) and the vocabulary (mapping from token (string) to tokenId (int)) must be exactly matched.
Batching
Batching is the act of sending multiple sentences through the model, all at once. If you only have one sentence, you can just build a batch with a single sequence:
Batching allows the model to work when you feed it multiple sentences. Using multiple sequences is just as simple as building a batch with a single sequence. There’s a second issue, though. When you’re trying to batch together two (or more) sentences, they might be of different lengths. If you’ve ever worked with tensors before, you know that they need to be of rectangular shape, so you won’t be able to convert the list of input IDs into a tensor directly. To work around this problem, we usually pad the inputs.
There’s something wrong with the logits in our batched predictions: the second row should be the same as the logits for the second sentence, but we’ve got completely different values!
This is because the key feature of Transformer models is attention layers that contextualize each token. These will take into account the padding tokens since they attend to all of the tokens of a sequence. To get the same result when passing individual sentences of different lengths through the model or when passing a batch with the same sentences and padding applied, we need to tell those attention layers to ignore the padding tokens. This is done by using an attention mask.
Attention masks are tensors with the exact same shape as the input IDs tensor, filled with 0s and 1s: 1s indicate the corresponding tokens should be attended to, and 0s indicate the corresponding tokens should not be attended to (i.e., they should be ignored by the attention layers of the model
Long Sequences
With Transformer models, there is a limit to the lengths of the sequences we can pass the models. Most models handle sequences of up to 512 or 1024 tokens, and will crash when asked to process longer sequences. There are two solutions to this problem:
- Use a model with a longer supported sequence length.
- Truncate your sequences.
Models have different supported sequence lengths, and some specialize in handling very long sequences. Longformer is one example, and another is LED. If you’re working on a task that requires very long sequences, we recommend you take a look at those models.
Otherwise, we recommend you truncate your sequences by specifying the max_sequence_length parameter:
Token type ids
 Token type can be used to add extra information. In the case of comparing 2 sentences it can be used to discern if a token belongs to the first sentence or the second.
Token type can be used to add extra information. In the case of comparing 2 sentences it can be used to discern if a token belongs to the first sentence or the second.
Dynamic padding
Note that we’ve left the padding argument out in our tokenization function for now. This is because padding all the samples to the maximum length is not efficient: it’s better to pad the samples when we’re building a batch, as then we only need to pad to the maximum length in that batch, and not the maximum length in the entire dataset. This can save a lot of time and processing power when the inputs have very variable lengths!
The function that is responsible for putting together samples inside a batch is called a collate function. It’s an argument you can pass when you build a DataLoader
Evaluating text-to-text generation models
What is Text Generation? - Hugging Face
- Perplexity
- Cross Entropy
Tokenizer - Normalization and pre-tokenization

Optimising LLM’s for speed and memory
Optimizing LLMs for Speed and Memory (huggingface.co)
In this guide, we will go over the effective techniques for efficient LLM deployment:
-
Lower Precision: Research has shown that operating at reduced numerical precision, namely 8-bit and 4-bit can achieve computational advantages without a considerable decline in model performance.
-
Flash Attention: Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
-
Architectural Innovations: Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are Alibi, Rotary embeddings, Multi-Query Attention (MQA) and Grouped-Query-Attention (GQA).
Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition weights will be used to signify all model weight matrices and vectors.
Values are either stored in either float32, bfloat16, or float16
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let’s assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- GPT3 requires 2 * 175 GB = 350 GB VRAM
- Bloom requires 2 * 176 GB = 352 GB VRAM
- Llama-2-70b requires 2 * 70 GB = 140 GB VRAM
- Falcon-40b requires 2 * 40 GB = 80 GB VRAM
- MPT-30b requires 2 * 30 GB = 60 GB VRAM
- bigcode/starcoder requires 2 * 15.5 = 31 GB VRAM
Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require tensor parallelism and/or pipeline parallelism.
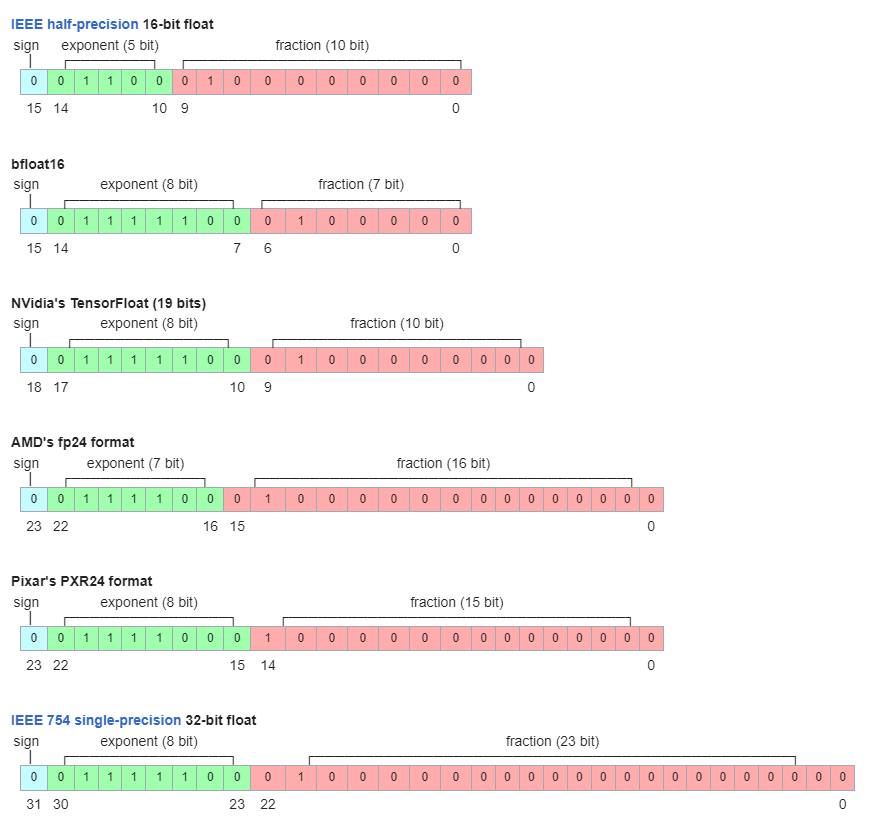
bfloat16 is used to keep the same dynamic range as 32 bit floating points but with only 8 bit precision.
Quantization
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model’s inference results as accurate as possible (a.k.a as close as possible to bfloat16). Note that quantization works especially well for text generation since all we care about is choosing the set of most likely next tokens and don’t really care about the exact values of the next token logit distribution. All that matters is that the next token logit distribution stays roughly the same so that an argmax or topk operation gives the same results.
-
- Quantize all weights to the target precision
-
- Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
-
- Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
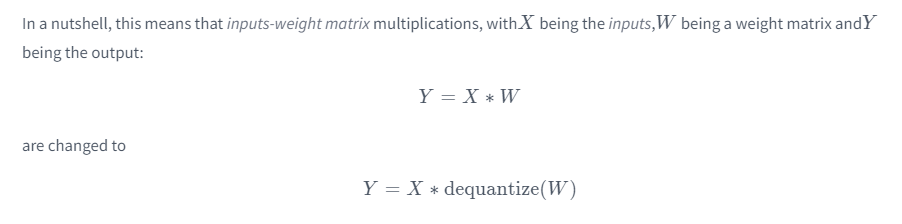
Therefore, inference time is often not reduced when using quantized weights, but rather increases. E.g. we trade off memory for computation time. However if it means that the model can be loaded into memory completely rather than getting continuously swapped, this CAN increase inference speed.
8 bit
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)4 bit
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
Flash attention
Today’s top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens. However, the peak GPU memory consumption for self-attention layers grows quadratically both in compute and memory complexity with number of input tokens (also called sequence length) that we denote in the following by N.
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel. Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the���QKT matrices to be40∗2∗�240∗2∗N2 bytes. For�=1000N=1000 only around 50 MB of VRAM are needed, however, for�=16000N=16000 we would need 19 GB of VRAM, and for�=100,000N=100,000 we would need almost 1TB just to store the���QKT matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.** **
Flash attention paper: [2205.14135] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arxiv.org)
In a nutshell, Flash Attention breaks the �×Softmax(���V×Softmax(QKT) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:

Info
By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives numerical identical outputs compared to the default self-attention layer at a memory cost that only increases linearly with�N Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM)
Info
In practice, there is currently absolutely no reason to not use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
GPU inference (huggingface.co)
Flash attention on amd gpu’s might be dicey / unsupported. To try out.
Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com)
![info] GPU inference (huggingface.co) Keep an eye on this list, we might get better amd support. Or MAYBE we use zuda to run this on AMD? Or maybe I just get an nvidia gpu lmao.
Flash Attention AMD
Supported Models and Hardware (huggingface.co)
ROCm/flash-attention: Fast and memory-efficient exact attention (github.com)
Supposedly flash attention should be enabled for rocm gpu’s using this magic docker container. The log output says otherwise.
2024-03-12T16:42:34.333521Z INFO download: text_generation_launcher: Successfully downloaded weights.
2024-03-12T16:42:34.333896Z INFO shard-manager: text_generation_launcher: Starting shard rank=0
2024-03-12T16:42:36.304187Z WARN text_generation_launcher: Could not import Flash Attention enabled models: Flash Attention is not installed.
Use the official Docker image (ghcr.io/huggingface/text-generation-inference:latest) or install flash attention with `cd server && make install install-flash-attention`
2024-03-12T16:42:36.304713Z WARN text_generation_launcher: Could not import Mamba: No module named 'mamba_ssm'
Issue template not found
Template Not Found When Using OpenAI format Chat Completion · Issue #1545 · huggingface/text-generation-inference (github.com) switching to using :latest-rocm docker tag and changing the model to be the -chat variant didn’t do anything useful.
Cause for concern
Might end up spending too much time getting the rocm support to work. I think best course of action is try and get the actual task “working” with cpu. Test that it can combine the stories as we hoped even if at the expense of a lot of memory. Then can look towards getting an nvidia card for flash attention.
Used links
Start Locally | PyTorch Template Not Found When Using OpenAI format Chat Completion · Issue #1545 · huggingface/text-generation-inference (github.com) Package text-generation-inference (github.com) Supported Models and Hardware (huggingface.co) Docker image support matrix — ROCm installation (Linux) (amd.com) Quick Tour (huggingface.co) ROCm/flash-attention: Fast and memory-efficient exact attention (github.com) AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU (huggingface.co)
Claude-3
Introducing the next generation of Claude \ Anthropic
Has a 200k token context BUT costs per million tokens 15 15 1.25
So they significantly price output tokens as more expensive than input tokens. So Should probably avoid running the model where we know it won’t be useful (e.g. missing keywords) and avoid repeating too many tokens.
Might want to batch user stories together to have fewer re-writes. But this comes at the cost of more memory and greater attention compute.
Gemini Pro: 0.125
but with a 128,000 token window.