Date: Monday, March 18, 2024
Work Undertaken Summary
- TMA02 Tutorial
- Document and send work to tutor
- Get Nvidia GPU installed and install CUDA (server os reinstall)
- Run google gemma 7b with cuda, quantization and flash attention
- Rule of mixtral 8x7b model
- Run mistal 7b model and perform needle-in-haystack test for attention / context length. Starts to have issues past 8k tokens.
- Take learnings and modify storyweaver design
Risks
Risk: Flash attention really important to project viability (long context length). Is built on CUDA so might be Nvidia specific.
Resolved by running mistral 7b with flash attention.
Time Spent
- 1hr on TMA02 tutorial
- 1.25hr on Documenting work and sending to Tutor
- 2.5hr on cuda install and os reinstall
- 1hr Run google gemma 7b with cuda, quantization and flash attention
- 3hr on investigating mixtral scaling
- 0.5hr on storyweaver design
- 0.5hr on literature reading
Questions for Tutor
It looks like the requirements of the project (small-enough parameter count for consumer GPU but large context window for the large amount of text) leaves a very limited pool of models to use. This combined with the extra work required to get a model setup and tune the prompt for the model probably means I will need to select and justify my model choice rather than choosing a bunch of models and evaluating them all.
Next work planned
Next work planned
Get Nvidia card Look into prompt engineering, really need to prevent the AI from just fabricating everything.
Continue investigating architectural innovations: Optimizing LLMs for Speed and Memory (huggingface.co)
Setup hugging face and try and enable flash attention due to large contexts to be used. GPU inference (huggingface.co)
Look into What is Text Generation? - Hugging Face
Look into [2010.11934] mT5: A massively multilingual pre-trained text-to-text transformer (arxiv.org)
Look into Text-to-Text Transfer Transformer (T5)
Look into What is Text Generation? - Hugging Face
It looks like our task matches closest with causal language modeling.
Link to original
Raw Notes
Environment setup commands installation
pip install huggingface_hub
pip install transformers
pip install torch
pip install accelerate
pip install -i https://pypi.org/simple/ bitsandbytes
(for flash-attn)
pip install ninja
pip install packaging
pip install wheel
MAX_JOBS=8 pip install flash-attn --no-build-isolationMixtral 8x7b
Mixtral 8x7b is a mixture-of-experts model, while it runs on my system it uses 56GB of ram and took about 10 minutes to produce 10 tokens. So is prohibitively slow on the available hardware.
Will try the mixtral 7b model instead.
Scaling
Model loaded = 4737MB 12197 tokens = 10441MB 37523 tokens = OOM 26663 tokens = 15609MB 29918 tokens = OOM 28k OOM 26971 = 15727 27247 = 15837
So about 0.45MB per token in memory usage
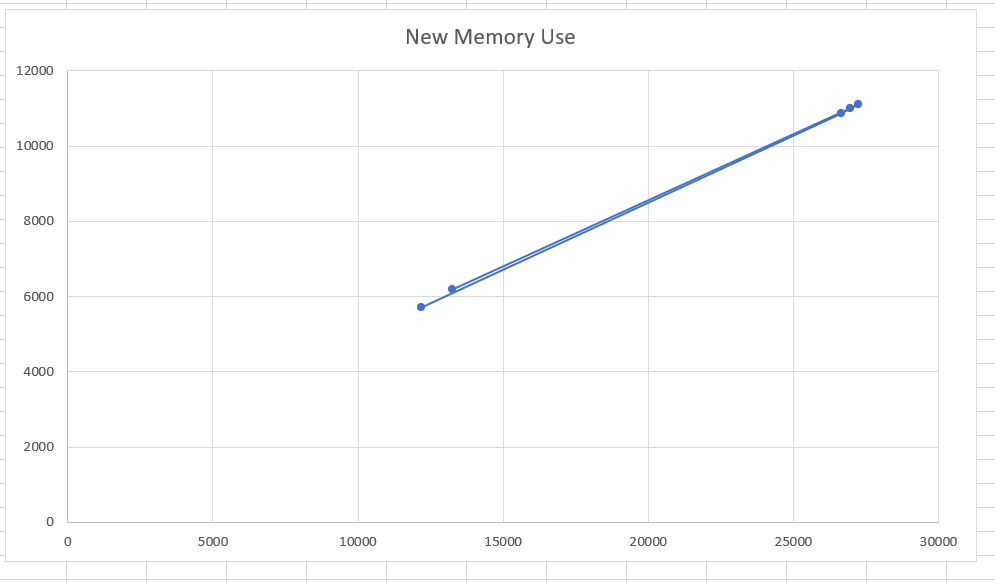
27k tokens = 11491 words = 2.37 tokens per word Which is about 22 pages of text in word approximately
Weirdly getting it to spit out 3000 more tokens didn’t change the memory usage, so memory usage is only relevant for input size? weird! I would have thought that the output tokens would continue to increase the memory usage.
This makes sense if the memory usage is tied only to the memory from the encoder section of the transformer.
It took 16.56 seconds to generate a 100 tokens. with 13269 token input. 26 seconds to generate 200 tokens. = 7.7 tokens a second. 56 seconds to generate 500 tokens = 9 tokens a second 324.92 seconds to generate 3000 tokens. = 10 tokens a second
Takeaways
Need to minimise churning through tokens without any edits, as we output about 10 tokens a second there will be a lot of time wasted on re outputing unchanged text. To minimise this:
- Batch user stories up, so that we output the changed specification less times in total
- Split the specification into smaller sections so that each section is more focused and is activated less frequently
- Put in place guards to prevent a user story from activating a section if the story isn’t relevant.
- Use simple guards like does the story contain the word booking
- Could maybe ask an LLM if the story is relevant to the description of the section? This model could then be a larger model / doesn’t have the same restrictions on context length so could be larger model that has better reasoning. All it would need to output is a yes or a no.
- Make the batching specific to the section, e.g. the Booking Section has stories 1, 2, 3 and the user section has stories 1, 3, 4 as 2 wasn’t relevant to the user section.